Cisco CCNA Cyber Ops SECFND 210-250, Section 6: Understanding Network Applications
6.2 DNS Operations
6.3 Recursive DNS Query
6.4 Dynamic DNS
6.5 HTTP Operations
6.6 HTTPS Operations
6.7 Web Scripting
6.8 SQL Operations
6.9 SMTP Operations
DNS Operations
DNS (Domain Name System) provides mappings between the host names and IP addresses, or other mappings. For example, DNS can map host names, such as host.example.com, to IP address, such as 192.168.40.100 (or the IPv6 address). DNS service enables access to the network resources by their names instead of having to remember their IP addresses.
In addition to mapping host names to IP addresses, DNS can perform various other types of mapping. Each mapping type is defined in a different type of RR (Resource Record). For example, an RR that maps a host name to an IPv4 address is called an A record, an RR that maps a domain name to a list of mail servers for that domain is called an MX record, and an RR that maps the name server for the domain is called an NS record. More resource record types such as AAAA (IPv6 A Record), and PTR, are discussed later in this topic.
The figure below shows an example from a Microsoft DNS server. In this example, the domain name is secure-x.local. The hq-srv.secure-x.local host is the name server for the secure-x.local domain, as configured by the NS record. The A records are used to map the host name to the IP address. For example, the hq-srv host name is mapped to the 192.168.1.2 IP address, the inside-srv host name is also mapped to the 192.168.1.2 IP address, and so on. The fully qualified domain names for these two host names are hq-srv.secure-x.local and inside-srv.secure-x.local

The client side of DNS is called a DNS resolver. The DNS resource mapping process is accomplished by a DNS resolver sending a DNS query to a DNS server requesting the information that is defined in an RR.
DNS is a critical protocol for the network operations but weaknesses in the implementation of the DNS protocol allow it to be exploited and used for malicious activities. Security analysts should understand DNS operations to be able to recognize and detect DNS-based attacks.
DNS Ports
DNS primarily uses UDP port 53 for DNS queries and responses. DNS queries consist of a UDP request from the client followed by a UDP response from the DNS server. TCP port 53 is used when the DNS response data size exceeds 512 bytes, or for tasks such as zone transfers. Zone transfer is a type of DNS transaction. Zone transfer is used by the DNS administrators to replicate the DNS databases across a set of DNS servers.
DNS Distributed Database
DNS is a globally distributed, scalable, hierarchical, and dynamic database. No single DNS server on the Internet contains the entire DNS database. Authority over the different parts of the DNS database is delegated to different DNS servers in the Internet.
The DNS database is composed of a hierarchical domain name space that contains a tree-like data structure of linked domain names (nodes). The tree-like data structure for the domain name space starts at the root, which is represented by the “dot” (.), which is the topmost level of the DNS hierarchy. Although it is not typically displayed in user applications, the DNS root is represented as a trailing dot in an FQDN. For example, the right-most dot in “http://www.cisco.com.” represents the root zone. From the root zone, the DNS hierarchy is then split into subdomain (branches) zones.
Each FQDN is composed of one or more labels. Labels are separated with a dot (.), and may contain a maximum of 63 characters. An FQDN may contain a maximum of 255 characters, including the dot (.). Labels are constructed from right to left, where the label at the far right is the TLD for the domain name. For example, .com is the TLD (Top-Level Domain) for http://www.cisco.com because it is the label furthest to the right.
The following diagram illustrates a sample of the DNS hierarchy starting from the root (.). For example, everything below the .org TLD is in the .org domain, and everything below the .cisco.com domain name space is in the .cisco.com domain.
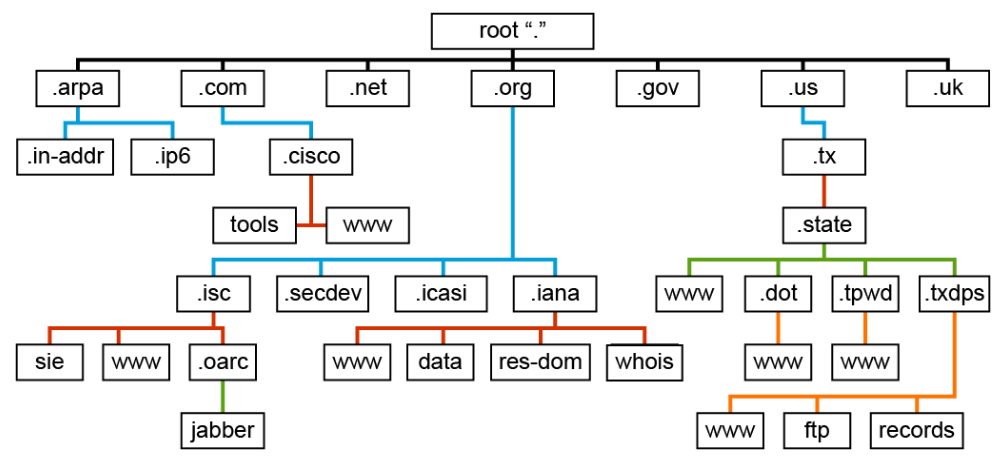
DNS Terminology
- Resource record: The RR defines the DNS data types that are stored in the DNS database. The most common types of RRs are for SOA, IP addresses (A and AAAA), SMTP mail servers (MX), name servers (NS), pointers for reverse DNS lookups (PTR), and domain name aliases (CNAME). An RR is composed of the following fields: NAME, TYPE, CLASS, TTL, RDLENGTH, and RDATA.
- Client device OSs or applications use very simple stub DNS resolvers. Typically, stub DNS resolvers issue DNS queries to the DNS recursive resolvers—not only for DNS information about the internal resources, but also for DNS information about publicly registered domains.
- DNS recursive resolver is a DNS server that processes the clients' DNS queries. The DNS recursive server queries the necessary authoritative DNS servers for the RR information, then the DNS recursive server provides the answer back to the DNS client. Typically, DNS recursive resolvers are internal to an organization and should only allow DNS queries from internal clients.
- Open DNS recursive resolvers are DNS recursive resolvers that allow queries from all IP addresses and are exposed to the Internet. Examples of public open DNS recursive resolvers include GoogleDNS (8.8.8.8) and Cisco OpenDNS (208.67.222.222 and 208.67.220.220). Attackers often scan for open DNS recursive resolvers to use them in reflection or amplification DDoS attacks. Organizations must exercise care in managing and monitoring their open DNS recursive resolvers.
- Authoritative DNS server is responsible for all the domain's RRs. The authoritative DNS server returns answers to the DNS queries with information that is stored in the RRs for a domain name space that is stored on the local server. Authoritative DNS servers provide the authoritative responses to the DNS recursive resolvers. The authoritative DNS servers are exposed to the Internet and generally allow DNS queries from all IP addresses.
The figure below shows the DNS query/response flow between the stub DNS resolver, the DNS recursive resolver, and the authoritative DNS server.

- Zones: In addition to being divided into domains, the DNS name space is partitioned into zones to simplify DNS database management. A zone is a contiguous portion of the domain name space in the DNS for which the administrative responsibility has been delegated to a single manager. A zone is the authoritative source for information about each domain that is included in the zone.
- A zone file is a text file that describes a DNS zone, and contains a list of the zone's resource records.
DNS RR Types
The following are examples of DNS resource record types:
- A record: Used to map host names to the IPv4 address of the host. In an A record, multiple IP addresses can correspond to a single host name. There can also be multiple host names each of which maps to the same IP address. There must be a valid A record in the DNS for the host.domain.name in order for a command, such as
telnet host.domain.name, to work. - AAAA record: AAAA is used to map hostnames to the IPv6 address of the host.
- MX record: MX maps a domain name to a list of mail servers for that domain.
- PTR record: A PTR points to a canonical name. The most common use is for implementing reverse DNS lookups, mapping an IP address to the hostname.
- NS record: An NS record identifies the DNS servers that are responsible (authoritative) for a zone.
- CNAME record: A CNAME record is used to specify that a domain name is an alias for another domain name, which is the "canonical" domain name.
- TXT record: A TXT record is used to associate any arbitrary text with a hostname. This record type is only used in specific cases such as Domain Keys Identified Mail, used as a method to detect email spoofing.
- SOA record: Each zone contains an SOA record. The SOA record identifies the name server that is the best source of information for the data within the zone. The SOA record also contains various other parameters that define the behavior of the DNS server.
The nslookup Utility
The nslookup utility is available on many operating systems, such as Windows and Linux, for querying the DNS database for domain names, IP address mapping, or any specific DNS record.
The examples below are taken from a Cisco lab environment, .public and .private are used instead of .com and .local to avoid conflicting with real and commonly used domain name spaces.
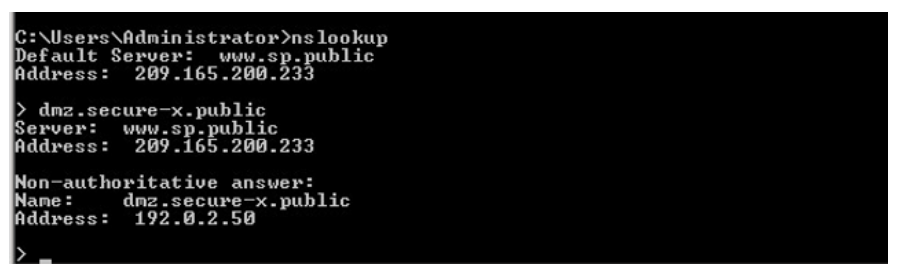
- A record: Using the
nslookuputility, it shows that the dmz.secure-x.public host that is resolved to the IP address of 192.0.2.50 from the 209.165.200.233 DNS server, and the 209.165.200.233 DNS server is not the authoritative DNS server for the secure-x.public domain.
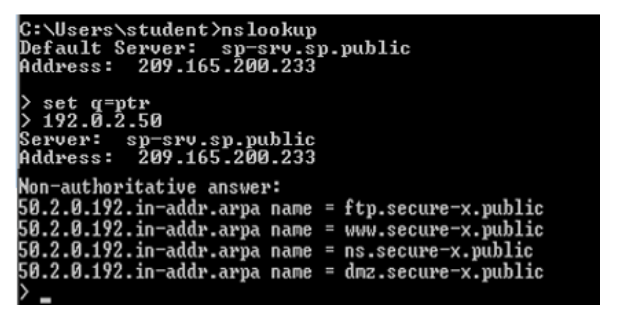
- PTR record: In this example, using the
nslookuputility, the setq=ptroption can be used to examine the PTR record. In this example, the PTR record from DNS shows 192.0.2.50 resolves to the various hostnames in the secure-x.public domain, such as dmz.secure-x.public.
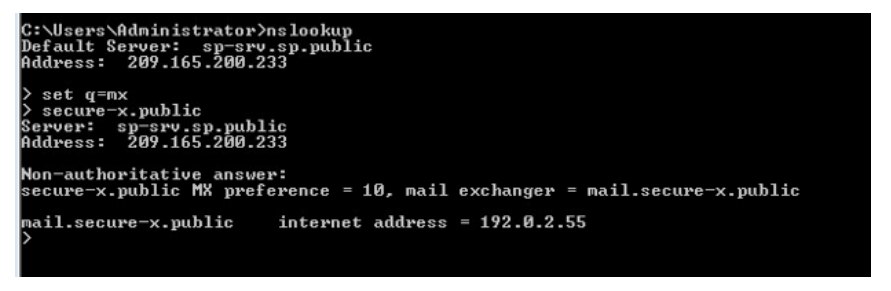
- MX record: In this example, using the
nslookuputility, theset q=mxoption can be used to examine the MX record. In this example, the MX record from DNS shows that 192.0.2.55 is the mail server for the secure-x.public domain.
Recursive DNS Query
Understanding how the recursive DNS query process works is important to an analyst when dealing with DNS-based attacks and interpreting packet captures with DNS flows.
When a DNS recursive resolver receives a DNS query for information for which it is not authoritative, it will recursively query the DNS architecture for the authoritative DNS server information.
Once the DNS recursive resolver has obtained the requested information from the authoritative DNS server, it will provide that information to the original DNS resolver using a DNS response message. In this case, the resource record will be non-authoritative (since the recursive DNS resolver is not authoritative for the requested information). A recursive DNS request requires more processing by the DNS server, when compared to a non-recursive DNS request.
The DNS recursive resolver may also have knowledge about the requested information that is stored in its local DNS cache. If the requested information is present in the DNS cache, then the recursive DNS resolver will respond with the locally cached resource record information.
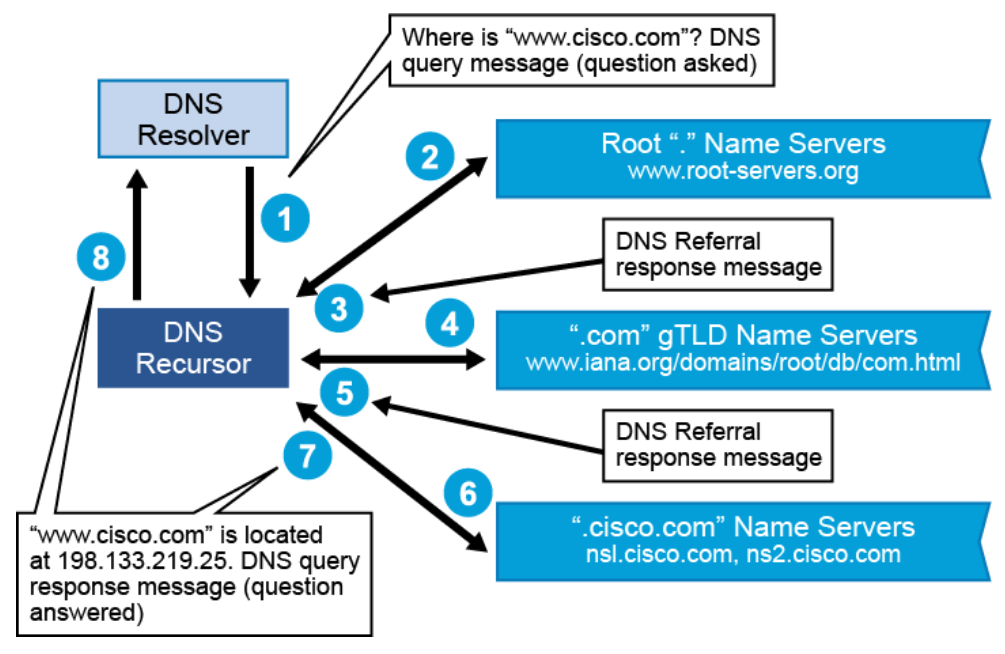
The above figure illustrates the recursive DNS process (assuming that nothing has been cached in the DNS recursor local DNS cache yet):
- The DNS resolver (DNS client) sends a query message to the DNS recursor (DNS recursive resolver) asking for the address of http://www.cisco.com
- The DNS recursor sends a query message to the root name servers looking for the .com domain name space.
- The root name servers send a DNS referral response message to the DNS recursor informing it to ask the gTLD (Generic Top-Level Domain) name servers for the .com domain name space.
- The DNS recursor sends a query message to the gTLD name servers looking for the .cisco.com domain name space.
- The gTLD name servers send a DNS referral response message to the DNS recursor informing it to ask the .cisco.com name servers, ns1.cisco.com or ns2.cisco.com, about this domain name space.
- The DNS recursor sends a query to ns1.cisco.com or ns2.cisco.com, asking for http://www.cisco.com
- The .cisco.com name servers, ns1.cisco.com or ns2.cisco.com, send an authoritative DNS query response message to the DNS recursor with the A (address) RR information for http://www.cisco.com
- The DNS recursor sends a DNS query response message to the DNS resolver with the A (address) RR information for http://www.cisco.com
Dynamic DNS
DDNS allows the automated discovery and registration of the client system’s public IP addresses. The DDNS client program on the end user device in the private network connects to the DDNS provider’s with a unique log in name, then the DDNS provider uses the name to link the discovered public IP address with a hostname in the domain name system.
Often, DDNS services use HTTP or HTTPS as the communication protocol between the client and the DDNS provider, since most environments usually allow HTTP or HTTPS traffic outbound.
DDNS is discussed in RFC 2136. DDNS can be used by Microsoft DNS servers for internal clients to register themselves to the Microsoft DNS servers, and it can be used in BIND 8 and above DNS servers, if configured to support DDNS.
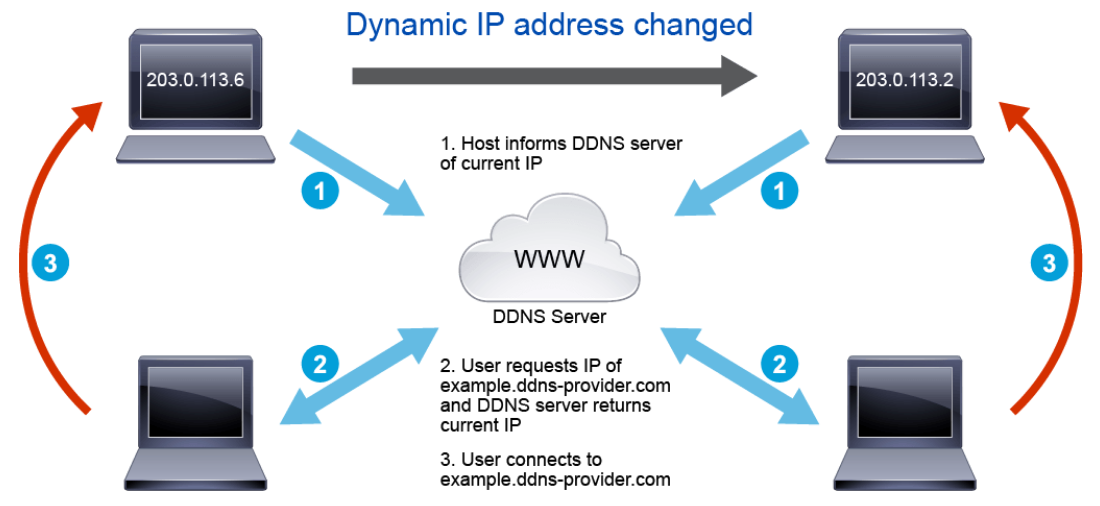
The figure above illustrates the basic DDNS operations:
- After the end-user host received a new dynamic IP address from the ISP, the DDNS client program on end-user host connects to the DDNS provider to inform the DDNS provider its new IP address, the DDNS provider links the end-user host new IP address to the end-used hostname in the domain name system.
- Another user queries for the IP address of the end-user hostname. In this example, the end-user hostname is example.ddns-provider.com.
- The other user receives the IP address of example.ddns-provider.com, and connects to example.ddns-provider.com using the IP address.
If the end-user host dynamic IP address is changed by the ISP, the end-user host informs the DDNS provider of its new IP address.
There are many DDNS providers that offer free and fee-based DDNS service. DDNS is a useful service with numerous legitimate applications. One of the primary DDNS use cases involves enabling connections to networks that rely on dynamic IP address ranges. Dynamic IP addressing tends to be more ubiquitous on residential networks, so that when home Internet users wish to host a website or connect to their home VPN, they often rely on a DDNS service. The DDNS provider maps a new subdomain (based on a list of existing domains that are owned by the DDNS provider) to the DDNS client’s dynamic IP address that is currently provisioned by the ISP.
Like all good and useful Internet services, threat actors have used DDNS for malicious purposes. In order to launch an attack that involves malicious intent while maintaining a persistent connection to a CnC server, or for data exfiltration from a victim network, an attacker must first configure the networking infrastructure. DNS is a primary consideration in the attacker’s larger decision process. One decision the attacker must make is whether to use domain names or IP addresses.
Obviously, not using domain names and hard-coding the CnC traffic to an IP address reduces the attack flexibility, since the command and control server may be quickly identified and disabled.
To use domain names, attackers can register their domains with a stolen credit card, compromise a legitimate registrar account and create new DNS records, or use a DDNS service. Registering a domain with a stolen credit card is not optimal for longer duration attacks, because the registrar will disable the domain and account once the fraud is discovered. Compromising an existing registrar customer account is resource-intensive and will not scale well for attacks requiring multiple domains.
Attackers now frequently choose to use a DDNS service, where the subdomains can be quickly and easily generated. Data that has been obtained by the Cisco Cloud Web Security research team shows that the block rate for DDNS-based domain web traffic is nearly 20%, while the average block rate for all other web traffic is less than 1%. There are also quite a few DDNS-based domains that are blocked with almost 100% frequency.
HTTP Operations
From the 2016 Cisco Annual Security Report, Cisco analyzed web traffic and determined that HTTPS requests have been gradually (but significantly) increasing since January 2015. For example, 24% of the web requests in January 2015 used the HTTPS protocol; the rest of them still used HTTP.
Security analysts should have a good understanding of the HTTP protocol operations since many attacks involve using HTTP. Security analysts should be able to analyze traffic captures that contain HTTP traffic to identify anomalies in the HTTP traffic.
HTTP Protocol Fundamentals
HTTP is a client/server protocol where the web browser is the client and the web server is the server. HTTP is a stateless application layer protocol. The default port for HTTP is TCP port 80, but other ports can be used.

A client’s web browser sends an HTTP request to the web server. An HTTP request has three parts:
- The HTTP request method, URI, and the HTTP protocol name and version
- The HTTP request headers are used to define the operating parameters of the HTTP transaction, and to provide information about the client.
- The HTTP request body
The web server sends an HTTP response to the client’s web browser. An HTTP response has three parts:
- HTTP protocol name and version, and the status code. For example, a status code of 200 means the processing of the HTTP request was successful.
- The HTTP response headers are used to define the operating parameters of the HTTP transaction, and to provide information about the web server.
- The HTTP response body
URI and URL
The URI identifies a resource either by location, or a name, or both. The official register of URI scheme names is maintained by IANA, at http://www.iana.org/assignments/uri-schemes. For each scheme, the RFC that defines the scheme is listed, for example “http:” is defined in RFC 2616.
A URL is a subset of a URI that defines the location of a specific resource and how to retrieve it. The part that makes a URI a URL is inclusion of the “access mechanism/protocol” or “network location,” such as http://, https://, and ftp://
For example, the http://www.example.com/index.html URL will request the file that is named index.html in the root directory of the www.example.com web server.
Below is an example of a URL and descriptions of each part of the URL.
http://www.example.cisco.com:80/video?docid=96673783583808&hl=en#00h01m15s
- Protocol: http (can also be https, ftp, and so on)
- Host: www.example.cisco.com
- Host (or Prefix) = www. Subdomain = example.cisco.com. Domain = cisco.com. Top-Level Domain = .com. - Port: If the port is not specified, port 80 is assumed.
- Path: /video. Path typically refers to a file or location on the web server. You can think of a path as a directory structure.
- Parameters: ?docid=96673783583808&hl=en. The docid=96673783583808 parameter in this example reference a specific video file in the path. The hl=en parameter specify the language, for example, setting the video subtitle to English.
- URL parameters are also referred to as “query strings," which contain extra information in the form of key-value pairs called parameters. URLs can have many parameters. Parameters start with a question mark (?) and are separated with an ampersand (&).
- Fragment or named anchor: #00h01m15s. Typically the fragment is used to refer to an internal section within a web document. In this case, the fragment means skip to 1 minute and 15 seconds into the video.
Some characters cannot be part of a URL (for example, a space), and some other characters have a special meaning in a URL. URL encoding is used to deal with this problem, for example, a space can be encoded as a “+” sign or as “%20”. “%20” is the percent encoding for the binary octet “00100000”, which in ASCII corresponds to the space character.
HTTP Request Methods
HTTP defines different request methods to indicate the desired action to be performed on the identified resource. The common HTTP request methods include GET, HEAD, POST, PUT, and DELETE, to name a few.
- The GET method retrieves data from the specified resource.
- The HEAD method asks for a response identical to that of a GET request, but without the response body
- The POST method creates data on the specified resource.
- The PUT method request is used to update data on the specified resource.
- The DELETE method deletes the specified resource.
HTTP Request and Response Packets Capture Example
The figure below shows a screenshot from Wireshark showing details of HTTP packets. The client’s HTTP GET requests are shown in red, and the web server’s responses are shown in blue. In this example, the client generated the HTTP GET request using the wget command from a Linux host.
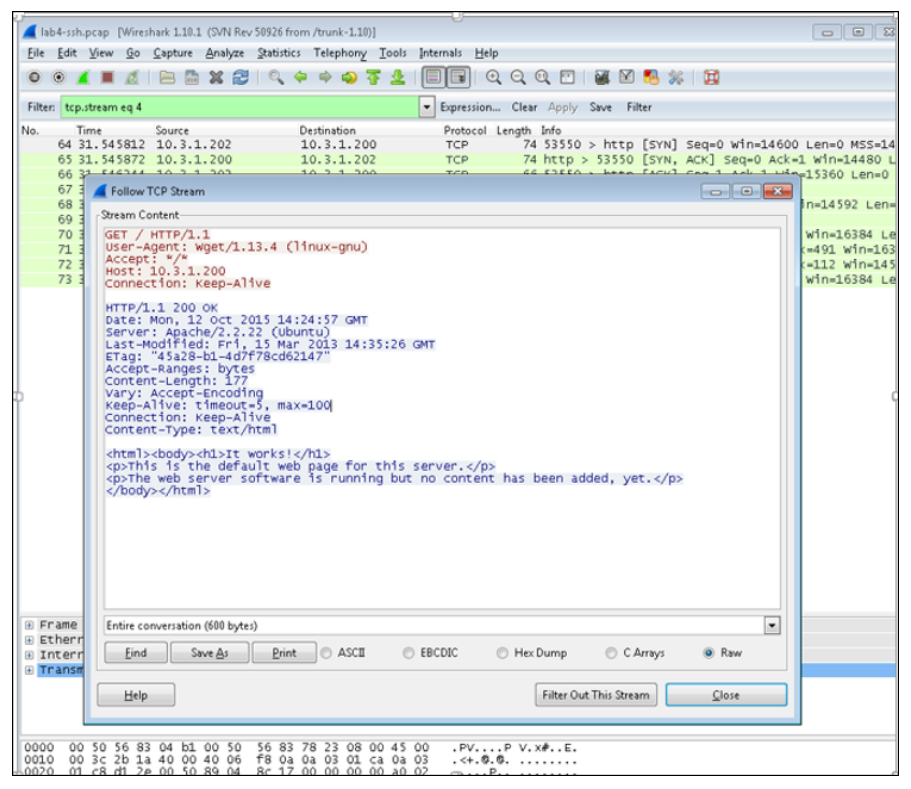
HTTP GET requests contain user agent information to help the web server identify the web browser and configuration of the client. In this example, the user agent is wget/1.13-4(linux-gnu). The user agent information that is sent by the web browser is used by the web server to identify the browser, the browser version, and the OS that the host is running on. The user agent is one of the fields in the HTTP header section of HTTP request. HTTP header fields are used to define the operating parameters of an HTTP transaction. A core set of the HTTP header fields is standardized in RFCs 7230, 7231, 7232, 7233, 7234, and 7235.
Web sites often include code to detect the web browser version and adjust the web page design according to the user agent information that is received. Various web browsers have a feature to spoof their identification to force certain server-side content. For example, the Firefox user agent changer add-on extension can be used to change the Firefox user agent. Attackers often manipulate the user agents in their attacks, such as embedding a malicious script in the user agent string.
In the user agent string example that is shown below, the browser is Firefox version 48.0 running on Windows 7:
Mozilla/5.0 (Windows NT 6.1; WOW64; rv:48.0) Gecko/20100101 Firefox/48.0
The user agent is one of the HTTP headers in the HTTP request. The other request headers in this example are Accept (content-types that are acceptable for the response), Host (identifies the web server), and Connection (control option for the connection). A core set of the HTTP header fields is standardized in RFCs 7230, 7231, 7232, 7233, 7234, and 7235. In this HTTP request example, there is no HTTP request body, the request body is optional in the HTTP request.
Examining the web server’s HTTP response in blue from the Wireshark screenshot, 200 is the OK status code. The HTTP response headers include information about the web server and version (Apache/2.2.22), the content type (text/HTML), and so on. The HTTP response body contains the requested web page:
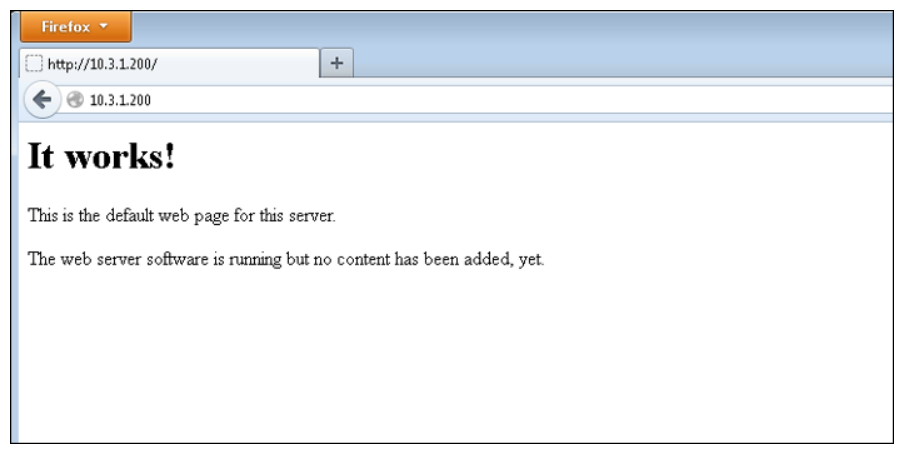
It works!
This is the default web page for this server.
The web server software is running but no content has been added, yet.
The figure below shows the actual web page that is being requested in this example.
HTTP Status Codes
The HTTP server responses are classified by a numerical status code. Status codes indicate the reasons behind successful and failed HTTP requests. The IANA maintains the official registry of the HTTP status codes.
Status codes starting with 1xx are Informational, 2xx are Success, 3xx are Redirection, 4xx are Client Error, and 5xx are Server Error.
Common status codes include the following:
- 100 = Continue: The server has received the request headers and the client should proceed to send the request body (in the case of a request for which a body needs to be sent; for example, a POST request).
- 200 = OK: The processing of the request that was sent by the client was successful.
- 301 = Moved Permanently: The resource has permanently moved to a different URI.
- 302 = Found: The requested resource resides temporarily under a different URI. The client is invited by a response with this code to make a second, otherwise identical, request to the new URL specified in the location field. However, many web browsers implemented the 302 status code in a manner that violates the HTTP/1.0 specification, changing the request type of the new request. Therefore, one of the other status codes that was added with the HTTP/1.1 specification is status code 307.
- 307 = Temporarily Moved: The request should be repeated with another URI; however, future requests should still use the original URI. The 307 status code indicates to client that the request method should not be changed when reissuing the original request. For example, a POST request should be repeated using another POST request.
- 401 = Unauthorized (Authentication Required): The request first requires authentication with the server.
- 403 = Forbidden: Access is denied.
- 404 = Not Found: The server cannot find the requested URI.
- 407 = Proxy Authentication Required: The request first requires authentication with the proxy.
- 500 = Internal Server Error: This generic web server error message is given when an unexpected condition is encountered and no more specific message is suitable.
HTTP Cookies
Another important HTTP feature an analyst needs to be aware of is the use of the HTTP cookies. Once an attacker has access to the web browser cookies for a particular web site, the attacker has access to all the information that is stored in the cookies.
An HTTP cookie is a small piece of data that is sent from the web server and stored in the user’s web browser while the user is browsing. Cookies are used by the web server to remember stateful information (such as items added in the shopping cart in an online store) or to record the user’s browsing activity (including clicking particular buttons, logging in, or recording which pages were visited in the past). Cookies can also be used to remember arbitrary pieces of information that were previously entered by the user in form fields such as name and address.
A web browser add-on, such as the Cookies Manager for Firefox (shown below), can be used to manage the Firefox browser’s cookies. In this example, one of the cookies for the cisco.com domain is the language preference, where it is currently set to en (English).
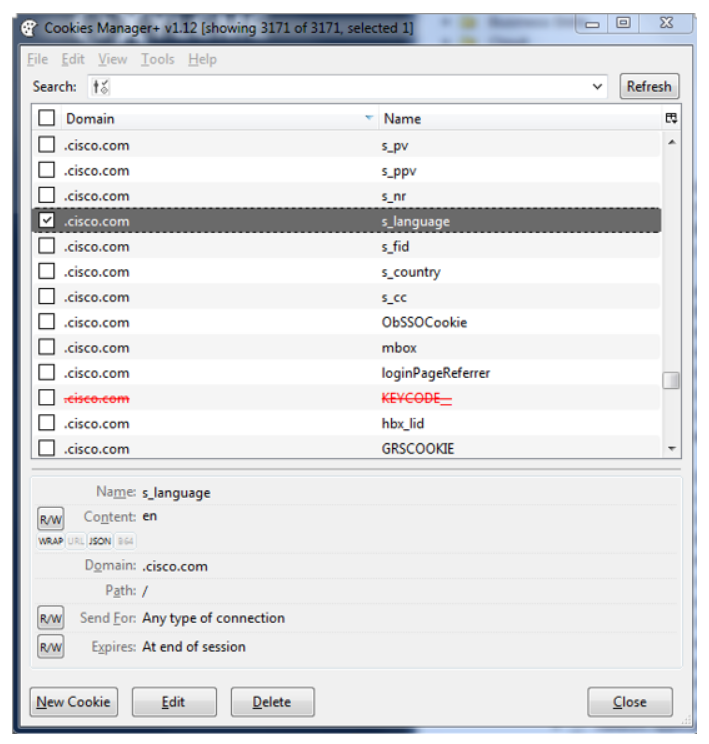
Cookies are passed between the web server and web browser using the Set-Cookie HTTP header field in the HTTP response, and the Cookie HTTP header in the HTTP request.
The web server sends the following to the web browser in the HTTP response header to create a cookie on the web browser:

The web browser sends the cookie information back to the web server in the HTTP request header:

For example, the web browser sends its first HTTP request to www.example.org:

The web server responds with two Set-Cookie headers:

The web browser sends another HTTP request to visit the ccna.html page on the website. This HTTP request contains the two cookies that the web server instructed the web browser to set:

The sessionToken cookie is a piece of data that can be used by the web server to identify a particular session. By examining the sessionToken cookie, the web server knows that this second HTTP request is related to the previous HTTP request. The web server answers by sending the requested web page, and possibly including more Set-Cookie headers in the HTTP response header in order to add new cookies, modify existing cookies, or delete cookies.
Many websites use cookies as identifiers for the user sessions. If a web site uses cookies as session identifiers, attackers can impersonate users’ requests by stealing, then using, the victims’ cookies. From the web server’s point of view, a request from the attacker then has the same authentication as the victim’s requests; thus the request is performed on behalf of the victim’s session.
For example, if the unencrypted HTTP traffic including the cookies on a network are intercepted by an attacker using a man-in-the-middle type attack, the attacker can use the intercepted cookies to impersonate a user and perform malicious tasks. This problem can be resolved by securing the web server and web browser communications by using the HTTPS protocol (HTTP over SSL/TLS) to encrypt the connection. The web server can specify a Secure flag while setting the cookies, which will cause the web browser to send the cookies only over an encrypted connection.
HTTP Referer
Referer is another HTTP request header. The referer is the address of the previous web page from which a link to the currently requested page was followed. For example, when a user clicks a link in a web page, the web browser sends an HTTP request to the web server that is serving the destination web page. The HTTP request headers include the referer header, which indicates the last page that the user was on (the page where the user clicked the link).
Note:
The word “referer” has been misspelled in the RFC and in most implementations, so that it has become standard usage and is now considered correct terminology.
The figure below shows an example of an HTTP GET request where the referer is http://www.cisco.com. In this example, the user clicked a link from the www.cisco.com home page to access another web page.
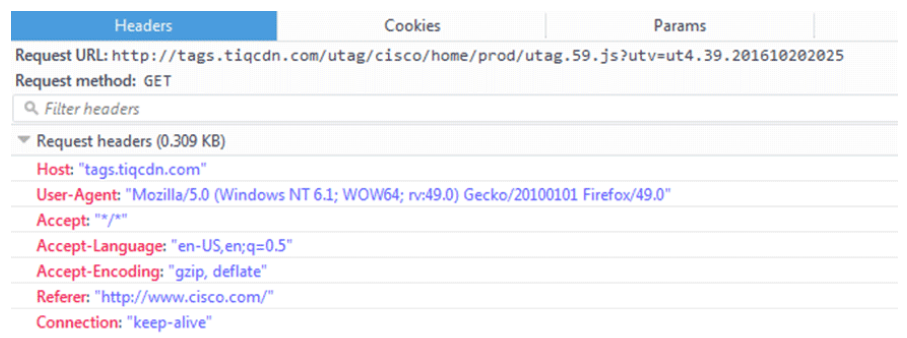
HTTPS Operations
As a protocol, HTTP is unencrypted, and therefore does not protect user data from interception or alteration. All data that is sent over HTTP is in plain text and can be read by anyone that manages to break into the connection between the browser and the web server. Unencrypted HTTP connections create a privacy vulnerability and expose potentially sensitive information.
In designing web applications, HTTPS should be used instead of HTTP whenever private data is being transmitted, such as passwords and credit card numbers. HTTPS is a combination of HTTP and TLS or its predecessor, SSL where HTTP runs on top of the TLS or SSL protocol. TLS or SSL is the network protocol that is used by HTTP to establish an encrypted connection to an authenticated peer over an untrusted network.
SSL is an older protocol which has weaknesses, such as the POODLE vulnerability, that has shown that SSL v3.0 is insecure. As a result of the POODLE vulnerability, SSL v3.0 is being disabled on web sites all over the world and for many other services as well. TLS v1.0 is based on SSL v3.0. TLS v1.1 and v1.2 are more secure and fixed many vulnerabilities present in SSL v3.0
Security analysts should understand HTTPS operations because attackers often hide their CnC traffic or exfiltrate data using HTTPS.
HTTPS basic operations include the following:
- HTTPS URLs begin with https:// and use TCP port 443 by default.
- The TLS or SSL connection between a client and server is set up by the TLS or SSL handshake. Once the TLS or SSL handshake is established, both parties use the agreed cryptographic algorithms to securely send messages to each other.
- HTTPS provides authentication of the web server. The web server's digital certificate allows the browser to identify the web server and to trust the web server it is communicating with, if the web server's digital certificate was signed by a certificate authority that is trusted by the web browser. Web browsers and/or the operating systems come with a pre-installed list of the certificate authority's digital certificates that are used to check the validity of the digital certificates of the web servers the browser connects to.
- HTTPS can also provide mutual authentication. If client authentication is also required, the web server can also authenticate the client using the client’s digital certificate. Most of the common web browsers support client side digital certificate. Client authentication is not typically implemented since most web sites do not really care who is connected to it. Most web sites are meant to be accessible by anyone.
- HTTPS provides HTTP headers and HTTP data traffic encryption between the client and the web server, which protects against eavesdropping. HTTP cookies, user agent, URL paths, form submissions, query parameters, and so on, are all encrypted.
Web browsers and other HTTPS clients are configured to trust a set of certificate authorities that can issue cryptographically signed digital certificates on behalf of the web service owners. These digital certificates communicate to the client that the web service host demonstrated ownership of the domain to the certificate authority at the time of the digital certificate issuance, preventing unknown or untrusted web sites from masquerading as the trusted secured web site.
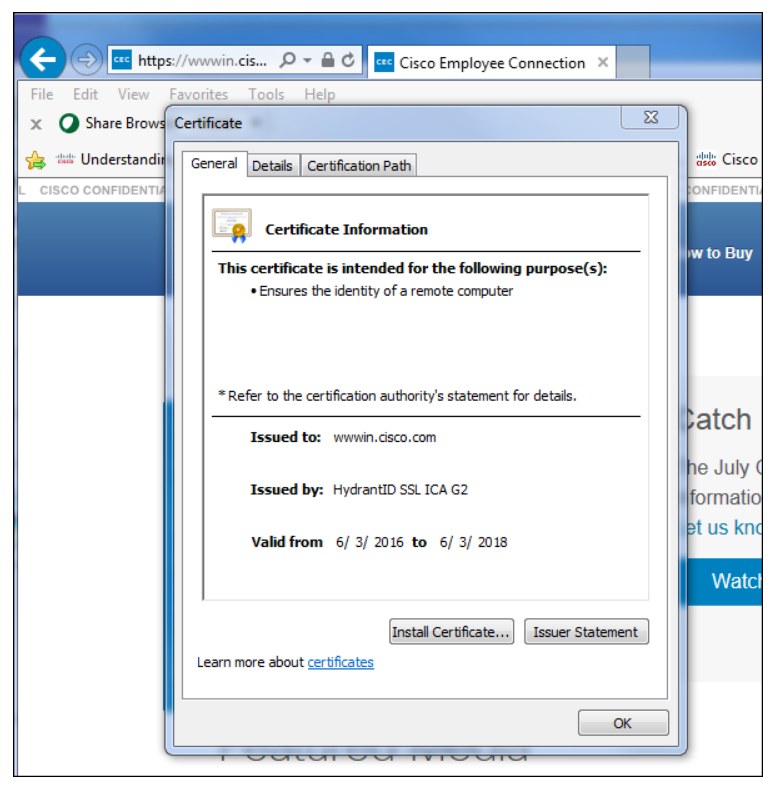
The figure above shows the http://www.cisco.com web server digital certificate that was used to validate the server identity to the web browser. Web browsers such as Internet Explorer commonly indicate that the connection is using HTTPS by showing the lock icon in the browser address bar. Users can click the lock icon to get information about the server digital certificate. In this example, the server digital certificate was signed by the HydrantID public certificate authority, and its validity will expire on 6/3/2018.
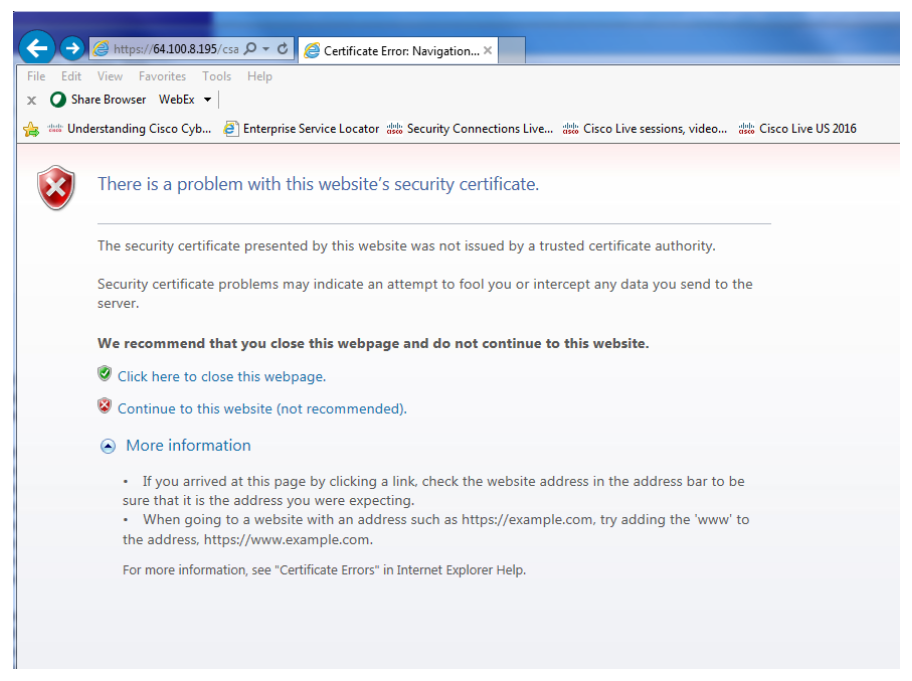
The figure above shows where the web server digital certificate that is presented to the browser was not issued by a trusted certificate authority. In this case, it is up to the user to accept the risk and continue or not. If the user ignores the certificate warning and continues to a malicious web site, that would break the HTTPS security instantly. The attacker can send any digital certificate of his own to impersonate the secured web server and have the victims connect to the attack’s web server.
Today’s cybercriminals often use HTTPS to obfuscate their outbound traffic to prevent eavesdropping or from being detected. One of the ways that organizations inspect HTTPS traffic is to deploy a next-generation firewall or web proxy that can act as an MITM to decrypt, inspect, and re-encrypt the SSL/TLS traffic. As a security analyst investigating security incidents with HTTPS traffic, one would often need to inspect next-generation firewall or web proxy logs to investigate the SSL/TLS decryption events.
Organizations performing SSL/TLS decryptions need to make sure that any government regulations around data confidentiality will not be violated by their SSL/TLS decryption actions.
Note:
Reference RFC 2818 for HTTP over TLS operations.
Web Scripting
Cybercriminals often deliver malware via the web and newly infected web sites are constantly being discovered. Security analysts should be aware of the dangers of web scripting. For example, malicious JavaScript allows cybercriminals to silently redirect the victim’s browser to load malware from a remote server, a technique that is known as “drive by” download.” Though entry-level security analysts do not require in-depth scripting knowledge, a basic understanding of some of the markup languages and scripts will help the security analyst to more efficiently analyze web-based attacks that use malicious scripts.
Web page content can be static and dynamic. Static content is generally created using a markup language such as HTML and XML. An HTML document filename usually ends in the .html extension. An HTML document is a text document that is read in by a web browser, and then rendered in the client’s web browser screen. The HTML document that is rendered in the web browser is human readable. XML defines a set of rules for encoding documents in a format that is both human-readable and machine-readable. CSS is used to specify the presentation of a document that was created using a markup language such as HTML or XML.
CSS is a style sheet language that can be used to describe the style of an HTML document or how the HTML elements should be displayed.
Server-Side and Client-Side Scripting
Web scripting is used to create dynamic content on a web page in addition to the static content. There are two approaches to implement the web scriptings:
- Server-side scripting is used in web applications development which involves using scripts on a web server to produce a response that is customized for each user's request to the website. The scripts may be written in any programming language, such as PERL, Python, PHP, and so on.
- Client-side scripting uses a language that is designed for the script to be executed by the client's web browser. Examples of client-side scripting languages include JavaScript, Visual Basic Script, and so on.
SQL Operations
SQL is used to query, operate, and administer relational database management systems such as Microsoft SQL server, Oracle, or MySQL. The general use of SQL is consistent across all database systems that support it; however, there are intricacies that are particular to each system. Database systems are commonly used to provide backend functionality to many types of web applications. In support of web applications, user-supplied web input data is often used to dynamically build SQL statements that interact directly with a database.
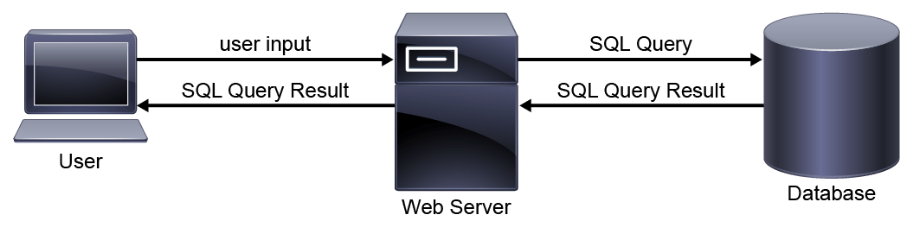
An analyst should understand how SQL is used to be able to recognize SQL based attacks such as the SQL injection attack. A SQL injection attack involves the alteration of SQL statements that are used within a web application by using attacker-supplied data. Insufficient input validation in web applications can expose them to SQL injection attacks. The effects of a successful SQL injection attack vary based on the targeted application and how that application processes the user-supplied data.
SQL functions include the following:
- Create databases and tables. The data in a database is stored in the tables. The table is a collection of related data entries and it consists of columns and rows. Columns contain the column name, data type, and any other attributes for the column. Rows contain the records or data for the columns.
- Define the data in the database and manipulate that data.
- Access the data in the database.
- Set the database permissions.
The following SQL commands are grouped according to the attacker’s goals:
- Exfiltrating data
-SELECT [fields] FROM [table] [...] - Modifying data
-UPDATE [table] SET [field] = [value] WHERE [condition]
-INSERT INTO [table] VALUES [...]
-TRUNCATE TABLE [table] - Modifying database structure
-DROP TABLE [table]
-ALTER TABLE [table] [...]
-DROP DATABASE
When dealing with data exfiltration, the analyst should respond quickly to prevent data from being sent out to the attacker. The analyst should determine the result of the SQL operation and search for abnormal traffic leaving the database/web servers, back to the attacker.
When dealing with data or database structure modification, the analyst should recognize that the data has been compromised, possibly deleted or modified. This comparison likely requires a comparison with an offline backup and restoration from a backup created prior to the attack.
SMTP Operations
Since the early 1990s, email has become the backbone of corporate communications. Each day, more than 100 billion corporate email messages are exchanged. As the level of email use rises, security becomes a greater priority. Mass spam campaigns are no longer the only concern. Today spam and malware are just part of a complex picture that includes inbound threats and outbound risks. Two of the major threats to an organization’s email system are:
- A flood of unsolicited and unwanted email, called spam, which wastes employee time through sheer volume and uses valuable resources like bandwidth and storage
- Malicious email, which comes in two basic forms of attacks: embedded attacks and targeted attacks
- Embedded attacks come in the form of viruses and malware that perform actions on the end device when clicked.
- Targeted attacks might direct employees to inadvertently browse malicious websites that distribute malware to computer endpoints and can mislead employees into releasing sensitive information like credit card numbers, social security numbers, or intellectual property. Targeted attacks are also known as directed attacks or phishing attacks.
In order to effectively mitigate email-based attacks, security analysts should understand how the mail delivery process works, and the contents of an SMTP conversation.
SMTP Terminology
These terms are necessary for a discussion involving mail transfer:
- MTA: The MTA (mail transfer agent), also called SMTP daemon, is a computer program or software agent that transfers electronic mail messages from one computer to another. Since personal computers do not send mail between themselves directly, they use client applications like MS Outlook which send mail to a groupware server, which then relay their mail through the MTA to some other mail domain. Another name for an MTA is an email gateway. The Cisco Email Security Appliance occupies this position in the network.
- DNS MX record: An MX record, or mail exchanger record, is a type of resource record that specifies the mail server (MTA) responsible for accepting email for that domain. MX records include a preference value that prioritizes which mail server should be used if there are multiple mail servers.
- DNS A record: Used to locate the IP address of the MTA specified by the MX record.
- Groupware server: A server that accepts, forwards, delivers, and stores messages on behalf of users who only need to connect to the email infrastructure. It also manages collaborative schedules, maintains calendars, and performs other related services to members interacting within a group.
- SMTP client: Will initiate the connection request to an SMTP server that is located within the same enterprise or out on the Internet.
- SMTP server: Will receive the connection request from the SMTP client. The transferring of mail from a groupware server to an MTA and then on to another MTA represents an exchange of roles between SMTP client to SMTP server.
- Mail user agent: The MUA is a software client application like Outlook that accesses a groupware server, for example, an exchange server, to send or receive mail.
- POP: The POP is an application-layer protocol that is used by the MUA to retrieve email from a mail server. A POP server listens on TCP port 110. POP has been developed through several versions, with POP3 being the last standard in common use. POP works by downloading all new messages from the mail server. Once the messages are downloaded, they are deleted from the email server.
- IMAP: The IMAP is also an application-layer protocol that is used by the MUA to retrieve email from a mail server. An IMAP server typically listens on TCP port 143. Virtually all modern email clients (mail user agent) support IMAP. IMAP allows you to access your email wherever you are, from any device. IMAP and the POP3 are the two most prevalent standard protocols for email retrieval.
- MAPI: The MAPI is also an application-layer protocol that is used by the MUA to retrieve email from a mail server and is primarily associated with Microsoft Exchange and Microsoft Outlook. It performs the services similar to IMAP but also provides other groupware functions that are associated with Outlook and Exchange.
SMTP Flow
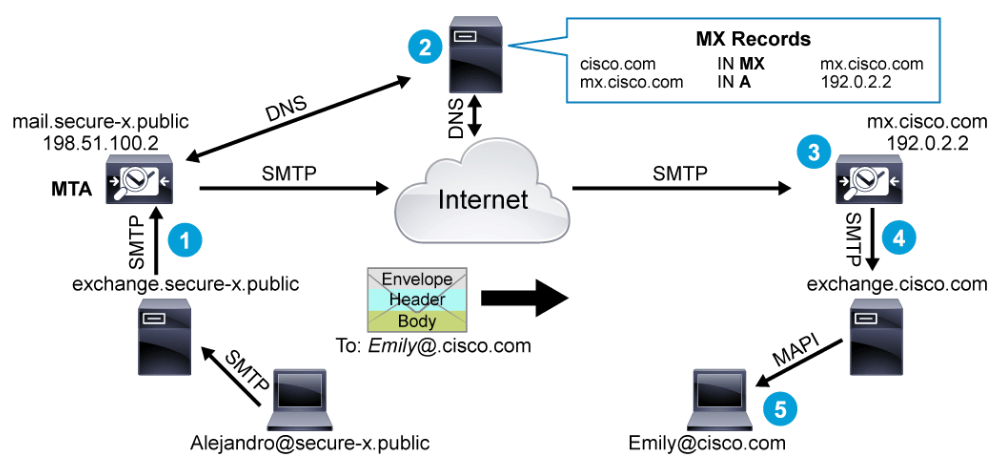
The above figure illustrates the stages of mail delivery:
- The MTA that is located at secure-x.public receives an email from Alejandro@secure-x.public to Emily@cisco.com. This MTA is known as the sending MTA.
- The sending MTA needs to determine the destination MTA IP address to send the email to, so it examines the domain portion of the recipient email address (the part that follows the @) and performs a query of the DNS MX record for cisco.com. The MX record points to the FQDN of the MTA at Cisco. The sending MTA then performs a DNS query for the A record for mx.cisco.com (192.0.2.2 in this example).
- The sending MTA sends the email to mx.cisco.com (which is the receiving MTA).
- Assuming that the reputation of smtp.secure-x.public is good, the receiving MTA performs an LDAP lookup to determine if the Emily user exists, then forwards the email to the mail server.
- The exchange mail server then sends the email to the mail user agent on Emily's computer through protocols such as POP, IMAP, or MAPI, and so on. Here, MAPI is the protocol that is used by the MUA.
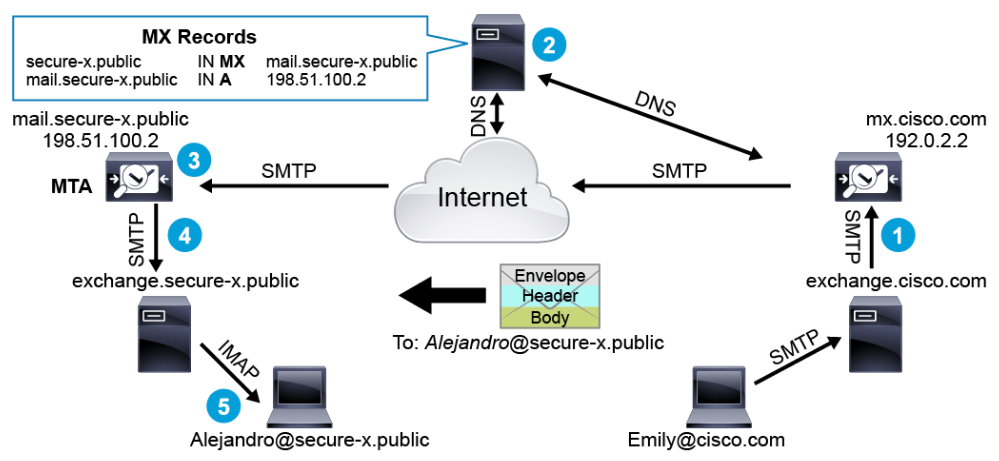
The figure below shows the mail delivery process when Emily replies to the received email. Here, IMAP is used by Alejandro to retrieve the email from the exchange mail server instead of MAPI.
SMTP Conversation
The figure shows the three parts of the SMTP conversation.

The events occur sequentially:
- Envelope: The SMTP envelope specifies the recipient and the sender
- Headers: The headers are sent after receiving a 354 (go ahead) SMTP reply code from the SMTP server. The headers contain the following information: sender's display name and email, the recipient's display name and email, and the subject and date. A blank line separates headers from any message content.
- Body: The body is an optional text region between the header and the one line containing a period (.). The terms "body," "message content," and "mail data" are used interchangeably. They all refer to the material that is transmitted after the DATA command is accepted and before the end of data indication is transmitted. A period (.) on one line indicates the end of data transmission.
SMTP Commands
SMTP commands transfer requests from the client to the SMTP server. Here are the most common commands:
- The HELLO (HELO) or EHLO (Extended HELLO) commands are used to identify the SMTP client to the SMTP server. The FQDN or the IP address of the SMTP client is usually sent as an argument together with HELO or EHLO commands. The HELO command is used to establish an SMTP session with another host. The EHLO command is used to establish an ESMTP session with another host. ESMTP specifies extensions to the SMTP standard to support additional commands. For example, ESMTP supports the SIZE command, which allows the receiving host to tell the sending host the maximum message size before the message is transmitted. Both the sending host and the receiving host must support the ESMTP protocol for the extended ESMTP capabilities to be utilized.
- The MAIL FROM command is used to initiate a mail transaction in which the mail data is delivered to an SMTP server which may, in turn, deliver it to one or more mailboxes. The MAIL FROM command specifies who the mail originator is.
- The RCPT TO command is used to identify an individual recipient of the mail data. Use multiples of this command to specify multiple recipients.
- The DATA command signifies that the email message body will follow. The receiver normally sends a 354 go ahead response, then treats the lines (strings ending in
sequences) as mail data from the sender.</li>
- The QUIT command specifies that the receiver must send an OK reply, and then close the transmission channel. The receiver must not intentionally close the transmission channel until it receives and replies to a QUIT command (even if there was an error). The sender must not intentionally close the transmission channel until it sends a QUIT command and should wait until it receives the reply (even if there was an error response to a previous command).
</ul>
SMTP Reply Codes
The three-digit SMTP reply codes define the server response to the SMTP client:
- The first digit denotes the success or failure of the SMTP command:
- 1 = command accepted but pending confirmation (example, 101 can’t open connection)
- 2 = success (example, 250 OK)
- 3 = okay so far (example, 354 go ahead, also called start mail input)
- 4 = temporary failure (example, 452 mailbox full)
- 5 = permanent failure (example, 550 user unknown) - The second digit categorizes the result:
- 0 = syntax
- 1 = information
- 2 = connection
- 3 = unspecified
- 4 = unspecified
- 5 = mail system - The third digit adds finer detail.
The following are a few more SMTP reply code examples:
- 211 = system status, or system help reply
- 220 (FQDN of server) = service ready
- 421 (FQDN of server) = service not available
- 451 = local error in processing
- 500 = command not recognized
- 502 = command not implemented